5. Construir Pipelines#
Como cientista de dados, por que você deveria se preocupar em otimizar seu fluxo de trabalho de ciência de dados? Vamos começar com um exemplo de um projeto básico de ciência de dados.
Imagine que você estivesse trabalhando com um conjunto de dados Iris. Você começou construindo funções para processar seus dados:
from typing import Any, Dict, List
import pandas as pd
def load_data(path: str) -> pd.DataFrame:
...
def get_classes(data: pd.DataFrame, target_col: str) -> List[str]:
"""Função que retorna as classes do conjunto de dados Iris."""
...
def encode_categorical_columns(data: pd.DataFrame, target_col: str) -> pd.DataFrame:
"""Função que codifica as colunas categóricas do conjunto de dados Iris."""
...
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
"""Função para dividir o conjunto de dados Iris em conjuntos de treino e teste."""
...
Após definir as funções, você as executa:
# Defina os parâmetros
target_col = 'species'
test_data_ratio = 0.2
# Rode as funções
data = load_data(path="data/raw/iris.csv")
categorical_columns = encode_categorical_columns(data=data, target_col=target_col)
classes = get_classes(data=data, target_col=target_col)
train_test_dict = split_data(data=categorical_columns,
test_data_ratio=test_data_ratio,
classes=classes)
Seu código funcionou bem e você nada viu de errado com a saída, então você acha que o fluxo de trabalho é bom o suficiente. No entanto, pode haver muitas desvantagens com um fluxo de trabalho linear como acima.

As desvantagens são:
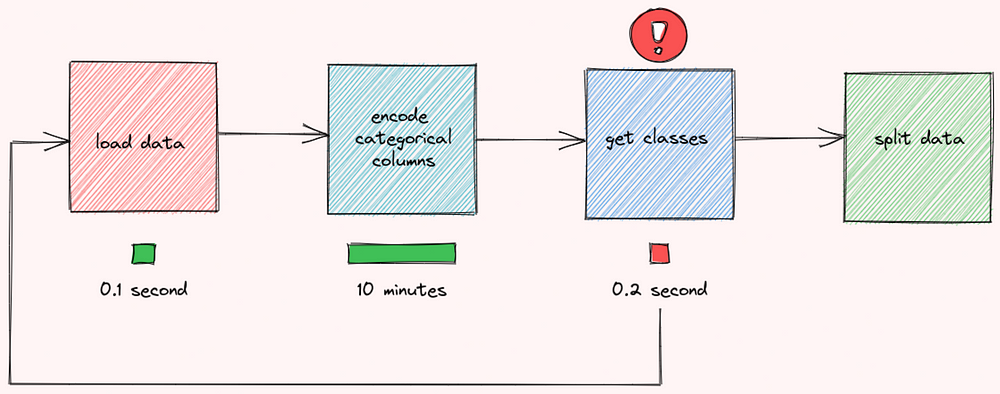
Se houver um erro na função
get_classes, a saída produzida pela funçãoencode_categorical_columnsserá perdida e o fluxo de trabalho precisará ser iniciado desde o início. Isso pode ser frustrante se levar muito tempo para executar a funçãoencode_categorical_columns.
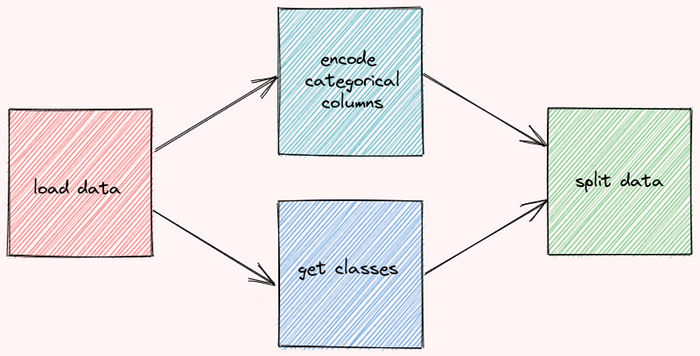
Como as funções
encode_categorical_columnseget_classesnão são dependentes uma da outra, elas podem ser executadas ao mesmo tempo:
Executar as funções dessa maneira também pode evitar o desperdício de tempo desnecessário em funções que não funcionam. Se houver um erro na função get_classes , o fluxo de trabalho será reiniciado imediatamente sem esperar que a função encode_categorical_columns termine.
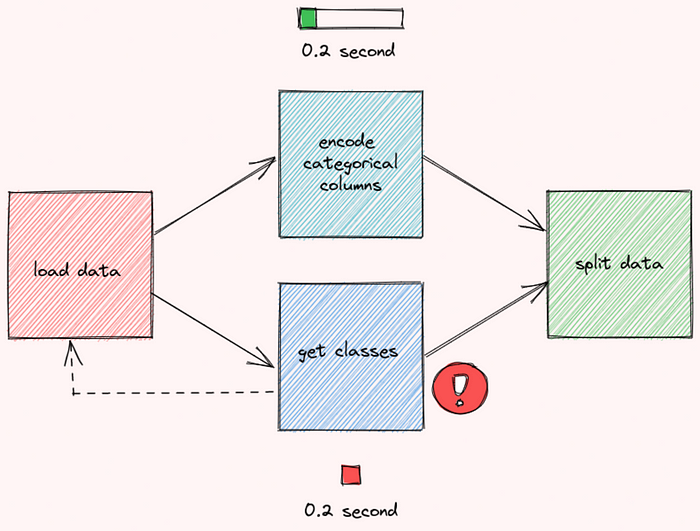
Agora, você pode concordar comigo que é importante otimizar o fluxo de trabalho de diferentes funções. No entanto, pode ser muito trabalhoso gerenciar manualmente o fluxo de trabalho.
Existe uma maneira de otimizar automaticamente o fluxo de trabalho adicionando apenas várias linhas de código? É aí que as bibliotecas de orquestração são úteis.