8.1. BentoML: Crie um Serviço de Predição Baseado em ML em Minutos#
8.1.1. O que é o BentoML?#
BentoML é uma biblioteca open-source do Python que permite que os usuários criem um serviço de predição baseado em machine learning em minutos, o que ajudar a diminuir a distância entre a ciência de dados e DevOps.
Para utilizar a versão da BentoML que será usada nessa seção, digite:
pip install bentoml==1.0.0a4
Para entender como a BentoML funciona, iremos usá-la para servir um modelo de segmentação de novos clientes baseado em suas personalidades.
8.1.2. Processar os Dados#
Comece baixando o dataset Customer Personality Analysis (Análise de Personalidade de Clientes) do Kaggle. A seguir, iremos processar os dados.
Como iremos utilizar o StandardScalar e o PCA para processar novos dados mais adiante, vamos salvar esses transformadores do scikit-learn em arquivos pickle na pasta processors.
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import pickle
# Escalar os dados
scaler = StandardScaler()
scaler.fit(df)
df = pd.DataFrame(scaler.transform(df), columns=df.columns)
# Reduzir a dimensionalidade
pca = PCA(n_components=3)
pca.fit(df)
pca_df = pd.DataFrame(pca.transform(df), columns=["col1", "col2", "col3"])
# Salvar os processadores
pickle.dump(scaler, open("processors/scaler.pkl", "wb"))
pickle.dump(scaler, open("processors/PCA.pkl", "wb"))
O código completo para ler e processar os dados pode ser encontrado aqui.
8.1.3. Salvar os Modelos#
A seguir, vamos treinar o modelo KMeans no conjunto de dados processado e salvar o modelo na loja de modelos locais da BentoML.
from sklearn.cluster import KMeans
import bentoml.sklearn
pca_df = ...
model = KMeans(n_clusters=4)
model.fit(pca_df)
bentoml.sklearn.save("customer_segmentation_kmeans", model)
Após executar o código acima, o modelo ficará salvo em ~/bentoml/models/. Você pode visualizar todos os modelos que estão guardados localmente ao rodar:
$ bentoml models list
Output:
Tag Module Path Size Creation Time
customer_segmentation_kmeans:o2ztyneoqsnwswyg bentoml.sklearn /home/khuyen/bentoml/models/customer_segmentation_kmeans/o2ztyneoqsnwswyg 10.08 KiB 2022-02-15 17:26:51
Note que o modelo está versionado com uma tag específica. Se salvarmos outro modelo com o mesmo nome, você deverá ver uma tag diferente:
$ bentoml models list
Tag Module Path Size Creation Time
customer_segmentation_kmeans:ye5eeaeoscnwswyg bentoml.sklearn /home/khuyen/bentoml/models/customer_segmentation_kmeans/ye5eeaeoscnwswyg 10.08 KiB 2022-02-15 18:54:50
customer_segmentation_kmeans:o2ztyneoqsnwswyg bentoml.sklearn /home/khuyen/bentoml/models/customer_segmentation_kmeans/o2ztyneoqsnwswyg 10.08 KiB 2022-02-15 17:26:51
Isso é muito bom, pois versionar o modelo irá nos permitir ir e voltar entre diferentes modelos.
O código completo para treinar e salvar o modelo pode ser encontrado aqui.
8.1.4. Criar os Serviços#
Agora que temos o modelo, vamos carregar o último modelo de segmentação de clientes e criar um serviço com ele em bentoml_app_pandas.py:
import bentoml
import bentoml.sklearn
from bentoml.io import NumpyNdarray, PandasDataFrame
import pickle
import numpy as np
import pandas as pd
# Carrega o modelo
classifier = bentoml.sklearn.load_runner("customer_segmentation_kmeans:latest")
# Cria um seviço com o modelo
service = bentoml.Service("customer_segmentation_kmeans", runners=[classifier])
Após definirmos o serviço, podemos utilizá-lo para criar uma função de API:
# Cria uma função de API
@service.api(input=PandasDataFrame(), output=NumpyNdarray())
def predict(df: pd.DataFrame) -> np.ndarray:
# Processa os dados
scaler = pickle.load(open("processors/scaler.pkl", "rb"))
scaled_df = pd.DataFrame(scaler.transform(df), columns=df.columns)
pca = pickle.load(open("processors/PCA.pkl", "rb"))
processed = pd.DataFrame(
pca.transform(scaled_df), columns=["col1", "col2", "col3"]
)
# Predição
result = classifier.run(processed)
return np.array(result)
O decorador @service.api declara que a função predict é uma API que recebe como entrada um PandasDataFrame e retorna como saída um NumpyNdarray.
Agora vamos testar o serviço em modo de debug ao rodar bentoml serve. Como o bentoml_app_pandas.py está no diretório src, rodamos:
$ bentoml serve src/bentoml_app_pandas.py:service --reload
Output:
[01:52:13 PM] INFO Starting development BentoServer from "src/bentoml_app_pandas.py:service"
[01:52:17 PM] INFO Service imported from source: bentoml.Service(name="customer_segmentation_kmeans", import_str="src.bentoml_app_pandas:service",
working_dir="/home/khuyen/customer_segmentation")
[01:52:17 PM] INFO Will watch for changes in these directories: ['/home/khuyen/customer_segmentation'] config.py:342
INFO Uvicorn running on http://127.0.0.1:5000 (Press CTRL+C to quit) config.py:564
INFO Started reloader process [605974] using statreload basereload.py:56
[01:52:21 PM] INFO Started server process [606151] server.py:75
INFO Waiting for application startup. on.py:45
INFO Application startup complete.
Agora podemos interagir com a API acessando http://127.0.0.1:5000 e clicando no botão “Try it out”:
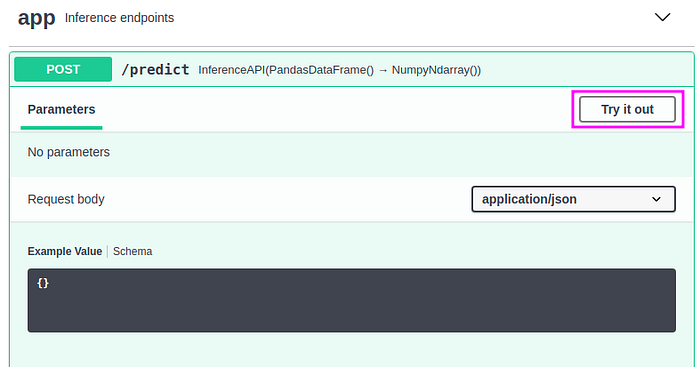
Inserindo os seguintes valores:
[{"Income": 58138, "Recency": 58, "NumWebVisitsMonth": 2, "Complain": 0,"age": 64,"total_purchases": 25,"enrollment_years": 10,"family_size": 1}]
… no corpo da Request deveria retornar o valor 1 . Isso significa que o modelo prevê que um cliente com essas características pertence à categoria 1.
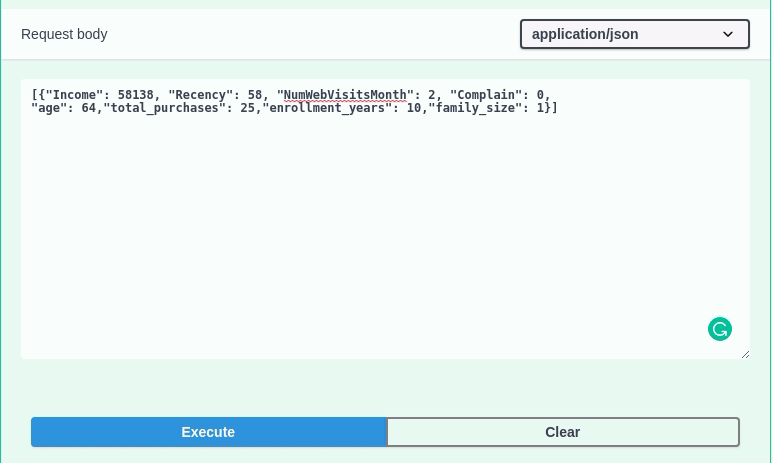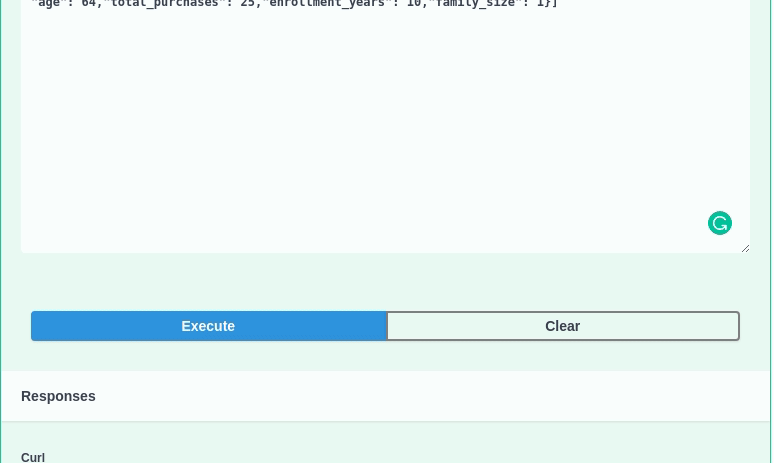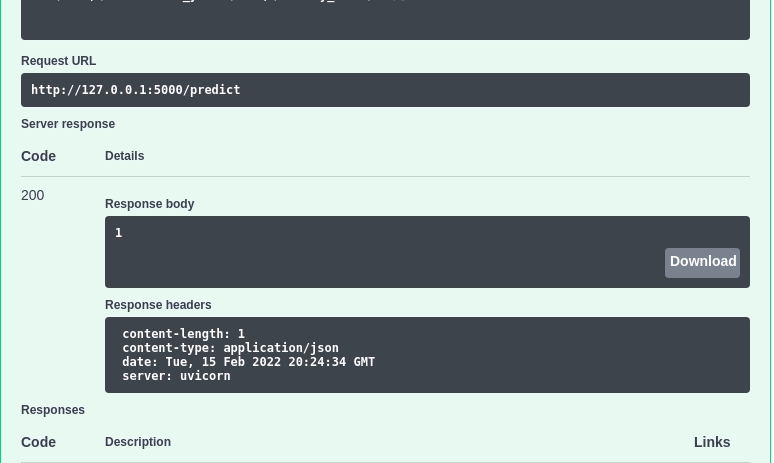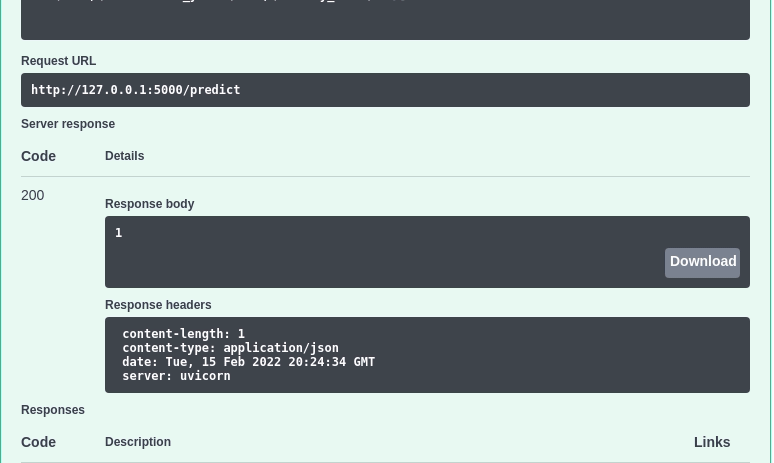
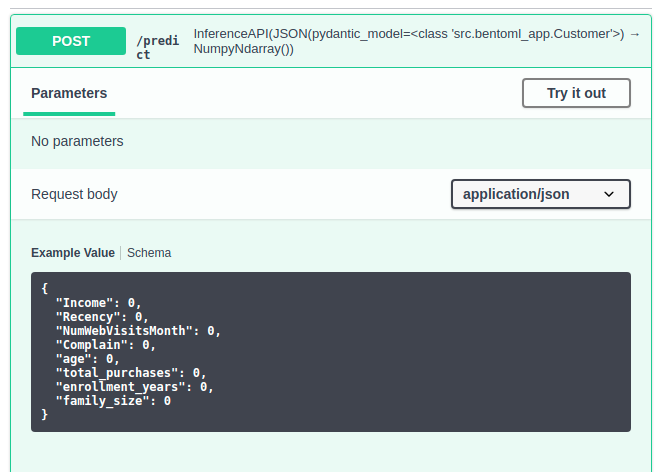
8.1.5. Criar um Modelo de Dados com pydantic#
Para termos certeza que os usuários insiram os valores corretos com os tipos de dados corretos na API, podemos usar o pydantic para criar um modelo de dados customizado:
from bentoml.io import JSON, NumpyNdarray
from pydantic import BaseModel
# Código que cria o serviço
...
# Cria um modelo de Customer (cliente)
class Customer(BaseModel):
Income: float = 58138
Recency: int = 58
NumWebVisitsMonth: int = 7
Complain: int = 0
age: int = 64
total_purchases: int = 25
enrollment_years: int = 10
family_size: int = 1
# Cria uma função de API
@service.api(input=JSON(pydantic_model=Customer), output=NumpyNdarray())
def predict(customer: Customer) -> np.ndarray:
df = pd.DataFrame(customer.dict(), index=[0])
# Código para processar e prever os dados
...
Agora você deve ver os valores padrões sob o corpo da Request.
O código completo para criar a API pode ser encontrado aqui.
8.1.6. Construir Bentos#
Após ter certeza que tudo está correndo bem, podemos começar a colocar o modelo, serviço e dependências dentro de um bento (esse nome faz referência à Bentō).
Para construir Bentor, comece criando um arquivo chamado bentofile.yaml no diretório do seu projeto:
service: "src/bentoml_app.py:service"
include:
- "src/bentoml_app.py"
python:
packages:
- numpy==1.20.3
- pandas==1.3.4
- scikit-learn==1.0.2
- pydantic==1.9.0
Detalhes sobre o arquivo acima:
A seção
includeinforma para a BentoML quais arquivos incluir em um bento. Nesse arquivo, incluimosbentoml_app.pye todos os processadores que salvamos anteriormente.A seção
pythoninforma para a BentoML quais bibliotecas Python são dependências para o serviço.
Agora estamos prontos para construir Bentos!
$ bentoml build
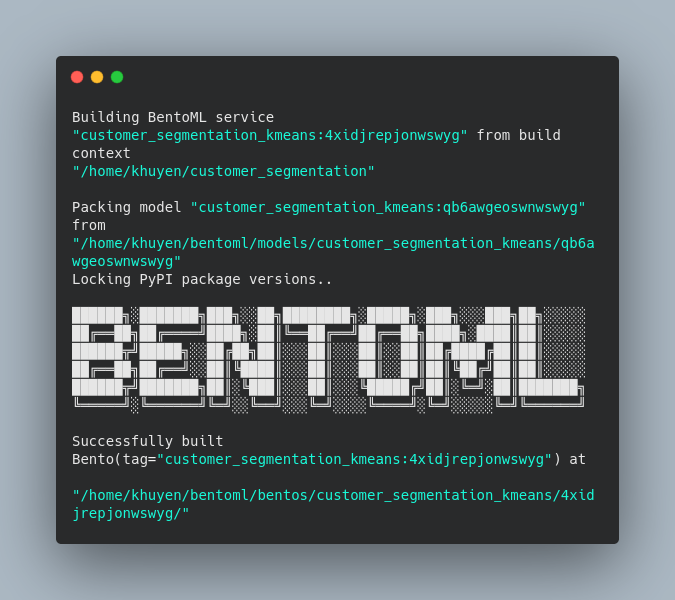
O Bentos ficará salvo no diretório ~/bentoml/bentos/<model-name>/<tag>. Os arquivos no diretório devem ser semelhantes aos abaixo:
.
├── apis
│ └── openapi.yaml
├── bento.yaml
├── env
│ ├── conda
│ ├── docker
│ │ ├── Dockerfile
│ │ ├── entrypoint.sh
│ │ └── init.sh
│ └── python
│ ├── requirements.lock.txt
│ ├── requirements.txt
│ └── version.txt
├── models
│ └── customer_segmentation_kmeans
│ ├── latest
│ └── qb6awgeoswnwswyg
│ ├── model.yaml
│ └── saved_model.pkl
├── README.md
└── src
├── processors
│ ├── PCA.pkl
│ └── scaler.pkl
└── src
├── bentoml_app.py
└── streamlit_app.py
Muito legal! Acabamos de criar uma pasta com o modelo, serviço, processadores, requisitos Python e um Dockerfile com poucas linhas de código!
8.1.7. Deploy no Heroku#
Agora que você tem um Bentos, você pode colocá-lo em um contêiner Docker ou fazer o deploy no Heroku. Como queremos criar um link pública para a API, iremos fazer o deploy para o Heroku Container Registry.
Comece instalando o Heroku, e faça o login para uma conta no Heroku através da linha de comando:
$ heroku login
Login no Heroku Container Registry:
$ heroku container:login
Criar um app Heroku:
$ APP_NAME=bentoml-her0ku-$(date +%s | base64 | tr '[:upper:]' '[:lower:]' | tr -dc _a-z-0-9)heroku create $APP_NAME
A seguir, vá para a o diretório docker do seu último Bentos construído. Para visualizar os diretórios do seu Bentos rode:
$ bentoml list -o json
[
{
"tag": "customer_segmentation_kmeans:4xidjrepjonwswyg",
"service": "src.bentoml_app:service",
"path": "/home/khuyen/bentoml/bentos/customer_segmentation_kmeans/4xidjrepjonwswyg",
"size": "29.13 KiB",
"creation_time": "2022-02-16 17:15:01"
}
]
Como nosso último Bentos está em ~/bentoml/bentos/customer_segmentation_kmeans/4xidjrepjonwswyg, iremos rodar:
cd ~/bentoml/bentos/customer_segmentation_kmeans/4xidjrepjonwswyg/env/docker
Transfomer seu Bentos em um contêiner e faça um push para o app Heroku que foi criado acima:
$ heroku container:push web --app $APP_NAME --context-path=../..
Lance o app:
$ heroku container:release web --app $APP_NAME
O novo app agora deve estar listado no dashboard do Heroku:
Clique no nome do app e então clique em “Open app” para abrir o aplicativo da sua API:
O link público da API dessa seção é https://bentoml-her0ku-mty0ndg3mza0ngo.herokuapp.com.
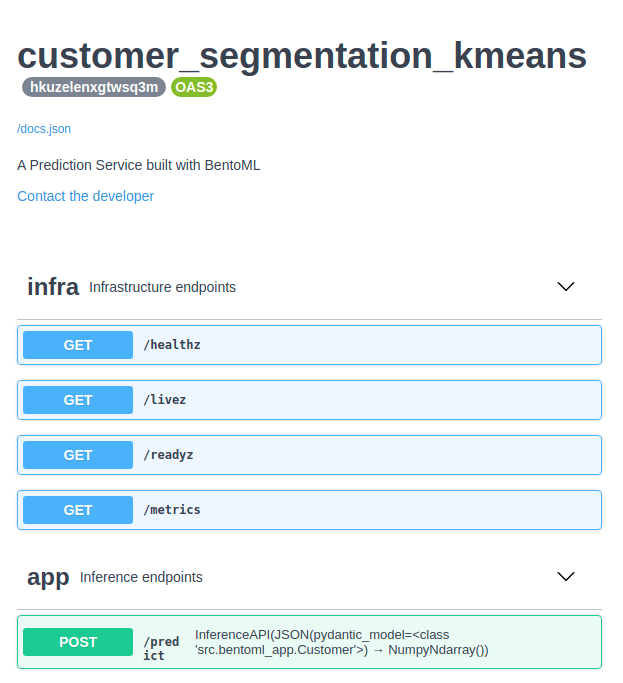
Agora você pode utilizar o link público para fazer requisições de predições com os dados de exemplo:
import requests
prediction = requests.post(
"https://bentoml-her0ku-mty0ndg3mza0ngo.herokuapp.com/predict",
headers={"content-type": "application/json"},
data='{"Income": 58138, "Recency": 58, "NumWebVisitsMonth": 2, "Complain": 0,"age": 64,"total_purchases": 25,"enrollment_years": 10,"family_size": 1}',
).text
print(prediction)
2
E é isso! Agora você pode enviar esse link para os outros membros da sua equipe para que eles possam criar um aplicativo web baseado em machine learning. Nenhum instalação e configuração são necessárias para usar seu modelo de machine learning. O quão incrível é isso?
Se você preferir criar uma UI (interface de usuário) simples, a próxima seção irá mostrar como fazer isso com o Streamlit.
8.1.8. Construir Uma UI Para Seu Serviço Utilizando Streamlit#
Se você quer que seus gerentes ou acionistas testem seu modelo, pode ser uma boa ideia construir uma simples UI para seu modelo utilizando Streamlit.
No arquivo streamlit_app.py, recebemos os inputs dos usuários e utilizamos esses inputs para construir uma requisição de predição.
import json
import math
import requests
import streamlit as st
st.title("Web App de Segmentação de Clientes")
# ---------------------------------------------------------------------------- #
# Recebe inputs do usuário
data = {}
data["Income"] = st.number_input(
"Income",
min_value=0,
step=500,
value=58138,
help="Renda doméstica anual do cliente",
)
data["Recency"] = st.number_input(
"Recency",
min_value=0,
value=58,
help="Quantidade de dias desde a última compra do cliente",
)
data["NumWebVisitsMonth"] = st.number_input(
"NumWebVisitsMonth",
min_value=0,
value=7,
help="Quantidade de visitas ao site da empresa no último mês",
)
data["Complain"] = st.number_input(
"Complain",
min_value=0,
value=7,
help="1 se o cliente reclamou nos últimos 2 anos, 0 caso contrário",
)
data["age"] = st.number_input(
"age",
min_value=0,
value=64,
help="Idade do cliente",
)
data["total_purchases"] = st.number_input(
"total_purchases",
min_value=0,
value=25,
help="Quantidade total de compras através do site, catálogo ou loja",
)
data["enrollment_years"] = st.number_input(
"enrollment_years",
min_value=0,
value=10,
help="Quantidade de anos que o cliente manteve laços com a empresa",
)
data["family_size"] = st.number_input(
"family_size",
min_value=0,
value=1,
help="Quantidade de pessoas na família do cliente",
)
# ---------------------------------------------------------------------------- #
# Realiza a predição
if st.button("Prever a categoria desse cliente"):
if not any(math.isnan(v) for v in data.values()):
data_json = json.dumps(data)
prediction = requests.post(
"https://bentoml-her0ku-mty0ndg3mza0ngo.herokuapp.com/predict",
headers={"content-type": "application/json"},
data=data_json,
).text
st.write(f"Esse cliente pertence à categoria {prediction}")
Rode o aplicativo Streamlit:
$ streamlit run src/streamlit_app.py
e então acesse http://localhost:8501. Você deve se depara com uma aplicação web como a da figura abaixo:

O aplicativo agora está mais intuitivo de ser testado.