5.1. Orquestre um projeto de ciência de dados em Python com Prefect#
5.1.1. O que é Prefect?#
Prefect é um framework de código aberto para criar fluxos de trabalho em Python. O Prefect facilita a criação, execução e monitoramento de pipelines de dados em escala.
Para instalar o Prefect, digite:
pip install prefect
Se estiver usando o Poetry, então digite:
poetry add prefect
5.1.2. Construa seu fluxo de trabalho com Prefect#
Para saber como o Prefect funciona, vamos encapsular o fluxo de trabalho apresentado acima.
5.1.2.1. Primeiro Passo — Criar Tarefas#
Uma Task é uma ação discreta em um fluxo. Comece transformando as funções definidas acima em tarefas usando o decorador @task :
from prefect import task
from typing import Any, Dict, List
import pandas as pd
@task
def load_data(path: str) -> pd.DataFrame:
...
@task
def get_classes(data: pd.DataFrame, target_col: str) -> List[str]:
"""Função que retorna as classes do conjunto de dados Iris."""
...
@task
def encode_categorical_columns(data: pd.DataFrame, target_col: str) -> pd.DataFrame:
"""Função que codifica as colunas categóricas do conjunto de dados Iris."""
...
@task
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
"""Função para dividir o conjunto de dados Iris em conjuntos de treino e teste."""
...
5.1.2.2. Segunda Etapa — Criar um Fluxo#
Um Flow representa todo o fluxo de trabalho gerenciando as dependências entre as tarefas. Para criar um flow, basta inserir o código para executar suas funções dentro do gerenciador de contexto with Flow(...).
from prefect import task, Flow
with Flow("data-engineer") as flow:
# Defina os parâmetros
target_col = 'species'
test_data_ratio = 0.2
# Defina as tarefas
data = load_data(path="data/raw/iris.csv")
classes = get_classes(data=data, target_col=target_col)
categorical_columns = encode_categorical_columns(data=data, target_col=target_col)
train_test_dict = split_data(data=categorical_columns, test_data_ratio=test_data_ratio, classes=classes)
Observe que nenhuma dessas tarefas é executada ao executar o código acima. O Prefect permite que você execute o flow imediatamente ou agende para mais tarde.
Vamos tentar executar o flow imediatamente usando flow.run() :
with Flow("data-engineer") as flow:
# Defina seu fluxo aqui
...
flow.run()
A execução do código acima fornecerá uma saída semelhante a esta:
└── 15:49:46 | INFO | Beginning Flow run for 'data-engineer'
└── 15:49:46 | INFO | Task 'target_col': Starting task run...
└── 15:49:46 | INFO | Task 'target_col': Finished task run for task with final state: 'Success'
└── 15:49:46 | INFO | Task 'test_data_ratio': Starting task run...
└── 15:49:47 | INFO | Task 'test_data_ratio': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Task 'load_data': Starting task run...
└── 15:49:47 | INFO | Task 'load_data': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Task 'encode_categorical_columns': Starting task run...
└── 15:49:47 | INFO | Task 'encode_categorical_columns': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Task 'get_classes': Starting task run...
└── 15:49:47 | INFO | Task 'get_classes': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Task 'split_data': Starting task run...
└── 15:49:47 | INFO | Task 'split_data': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Flow run SUCCESS: all reference tasks succeeded
Flow run succeeded!
Para entender o fluxo de trabalho criado pelo Prefect, vamos visualizar todo o fluxo de trabalho.
Comece instalando prefect[viz]:
pip install "prefect[viz]"
Em seguida, adicione o método visualize ao código:
flow.visualize()
E você deve ver a visualização do fluxo de trabalho do data-engineer como abaixo:
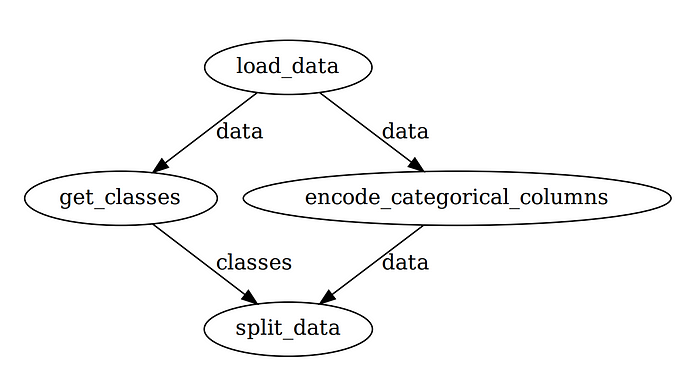
Observe que o Prefect gerencia automaticamente as ordens de execução entre as tarefas para que o fluxo de trabalho seja otimizado. Isso é muito legal para alguns pedaços de código adicionais!
5.1.2.3. Terceiro passo — Adicionar parâmetros#
Se você está experimentando frequentemente valores diferentes de uma variável, é ideal transformar essa variável em um Parameter:
test_data_ratio = 0.2
train_test_dict = split_data(data=categorical_columns,
test_data_ratio=test_data_ratio,
classes=classes)
Você pode considerar um Parameter como uma Task , exceto que ele pode receber entradas do usuário sempre que um fluxo for executado. Para transformar uma variável em um parâmetro, basta usar Parameter:
from prefect import task, Flow, Parameter
test_data_ratio = Parameter("test_data_ratio", default=0.2)
train_test_dict = split_data(data=categorical_columns,
test_data_ratio=test_data_ratio,
classes=classes)
O primeiro argumento de Parameter especifica o nome do parâmetro. default é um argumento opcional que especifica o valor padrão do parâmetro.
Executar flow.visualize novamente nos dará uma saída como abaixo:
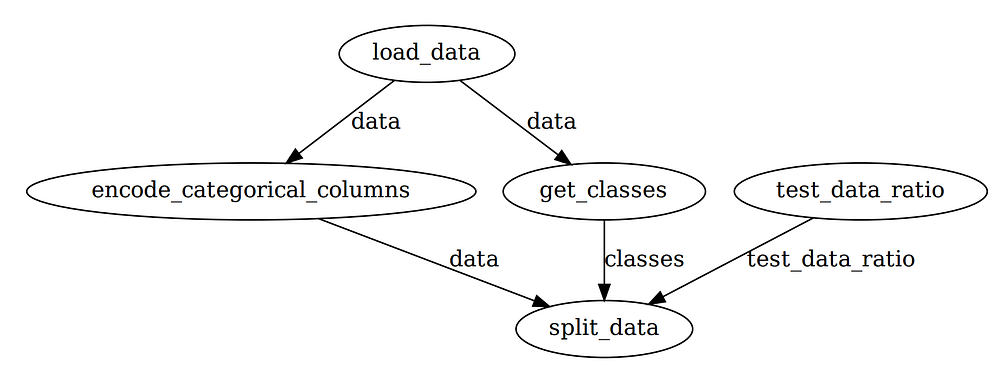
Você pode substituir o parâmetro padrão para cada execução:
adicionando o argumento
parametersaflow.run():
$ flow.run(parameters={'test_data_ratio': 0.3})
ou usando o Prefect CLI:
$ prefect run -p data_engineering.py --param test_data_ratio=0.2
ou usando um arquivo JSON:
$ prefect run -p data_engineering.py --param-file='params.json'
Seu arquivo JSON deve parecer com isso:
{"test_data_ratio": 0.3}
Você também pode alterar os parâmetros para cada execução usando o Prefect Cloud, que será apresentado na próxima seção.
5.1.3. Monitore seu fluxo de trabalho#
5.1.3.1. Visão geral#
O Prefect também permite monitorar seu fluxo de trabalho no Prefect Cloud. Siga esta instrução para instalar dependências relevantes para Prefect Cloud.
Depois que todas as dependências estiverem instaladas e configuradas, comece criando um projeto no Prefect executando:
$ prefect create project "Iris Project"
Em seguida, inicie um agente local para implantar nossos fluxos localmente em uma única máquina:
$ prefect agent local start
Em seguida, no final do seu arquivo, adicione:
flow.register(project_name="Iris Project")
Você deve ver algo parecido com o abaixo:
Flow URL: https://cloud.prefect.io/khuyentran1476-gmail-com-s-account/flow/dba26bea-8827-4db4-9988-3289f6cb662f
└── ID: 2944dc36-cdac-4079-8497-be4ec5594785
└── Project: Iris Project
└── Labels: ['khuyen-Precision-7740']
Clique na URL na saída e você será redirecionado para uma página de visão geral. A página Visão geral mostra a versão do seu fluxo, quando ele é criado, o histórico de execução do fluxo e seu resumo de execuções:
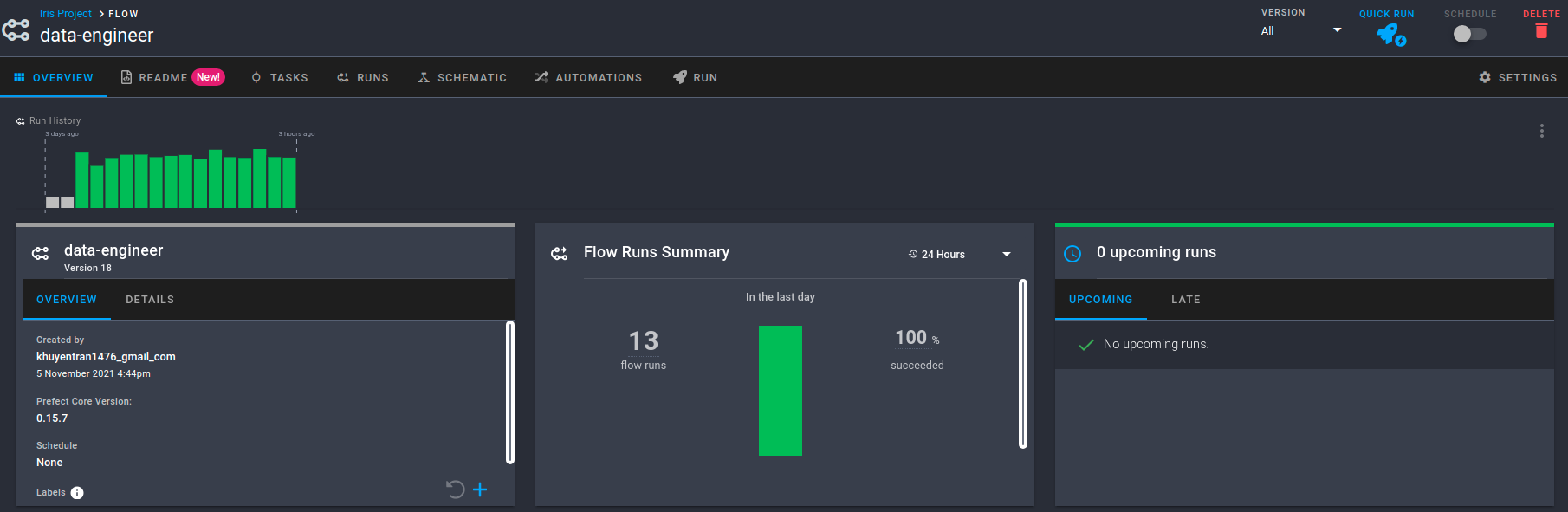
Você também pode visualizar o resumo de outras execuções, quando são executadas e suas configurações:
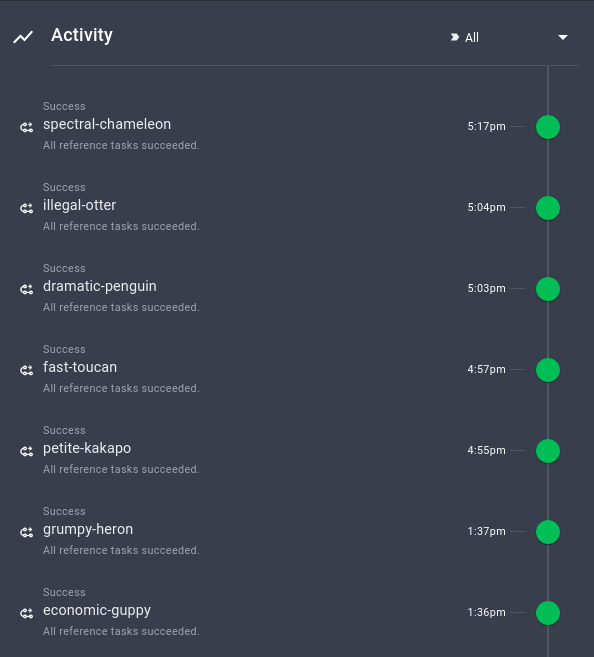
É muito legal como essas informações importantes são rastreadas automaticamente pelo Prefect!
5.1.3.2. Executar o fluxo de trabalho com parâmetros padrão#
Observe que o fluxo de trabalho está registrado no Prefect Cloud, mas ainda não foi executado. Para executar o fluxo de trabalho com os parâmetros padrão, clique em Quick Run no canto superior direito:
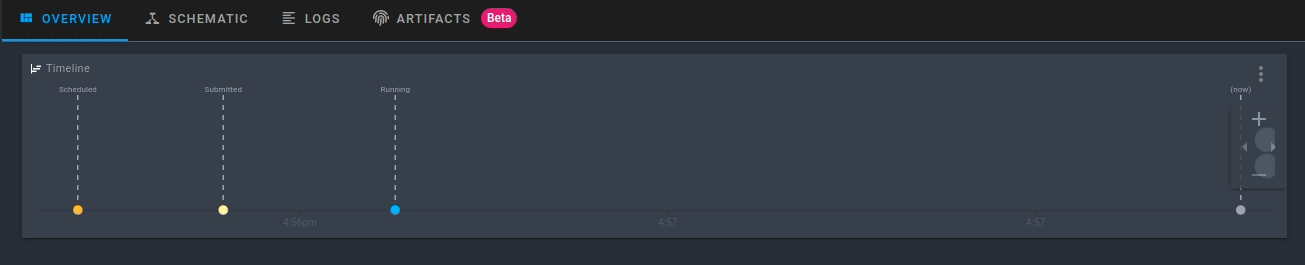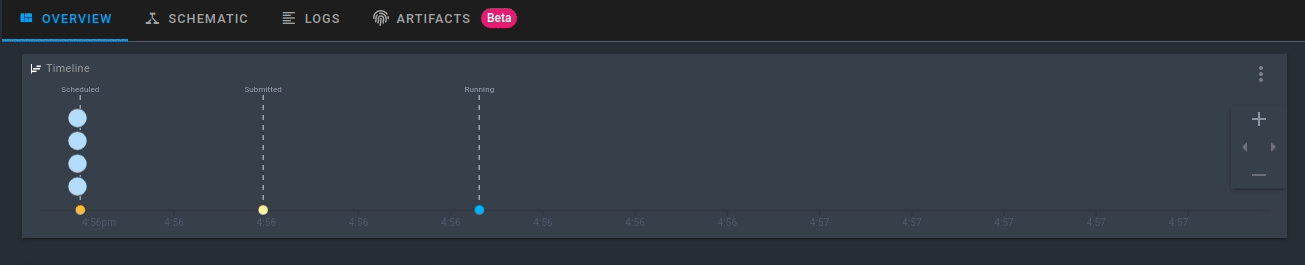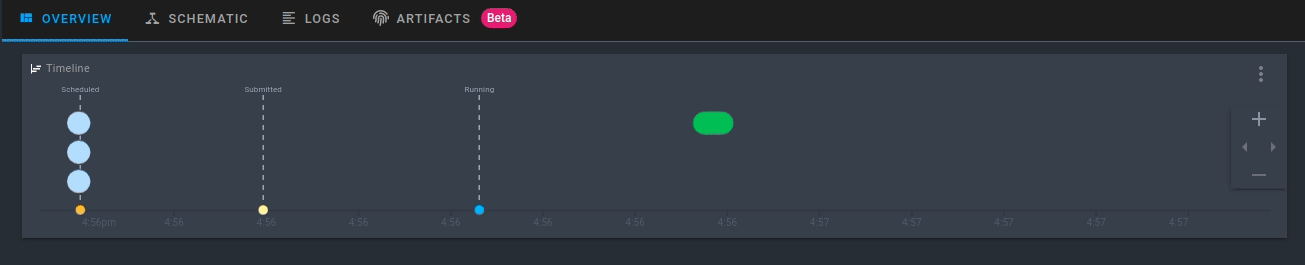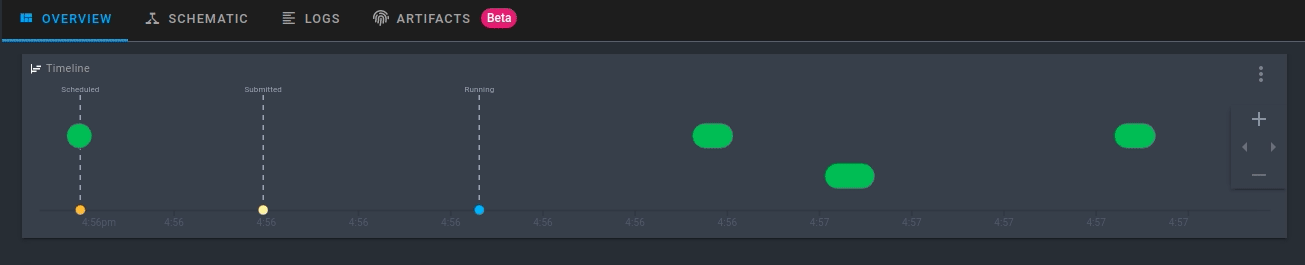
Clique na execução que é criada. Agora você poderá ver a atividade do seu novo fluxo executado em tempo real!
5.1.3.3. Execute o fluxo de trabalho com parâmetros personalizados#
Para executar o fluxo de trabalho com parâmetros personalizados, clique na guia Run e altere os parâmetros em Inputs:
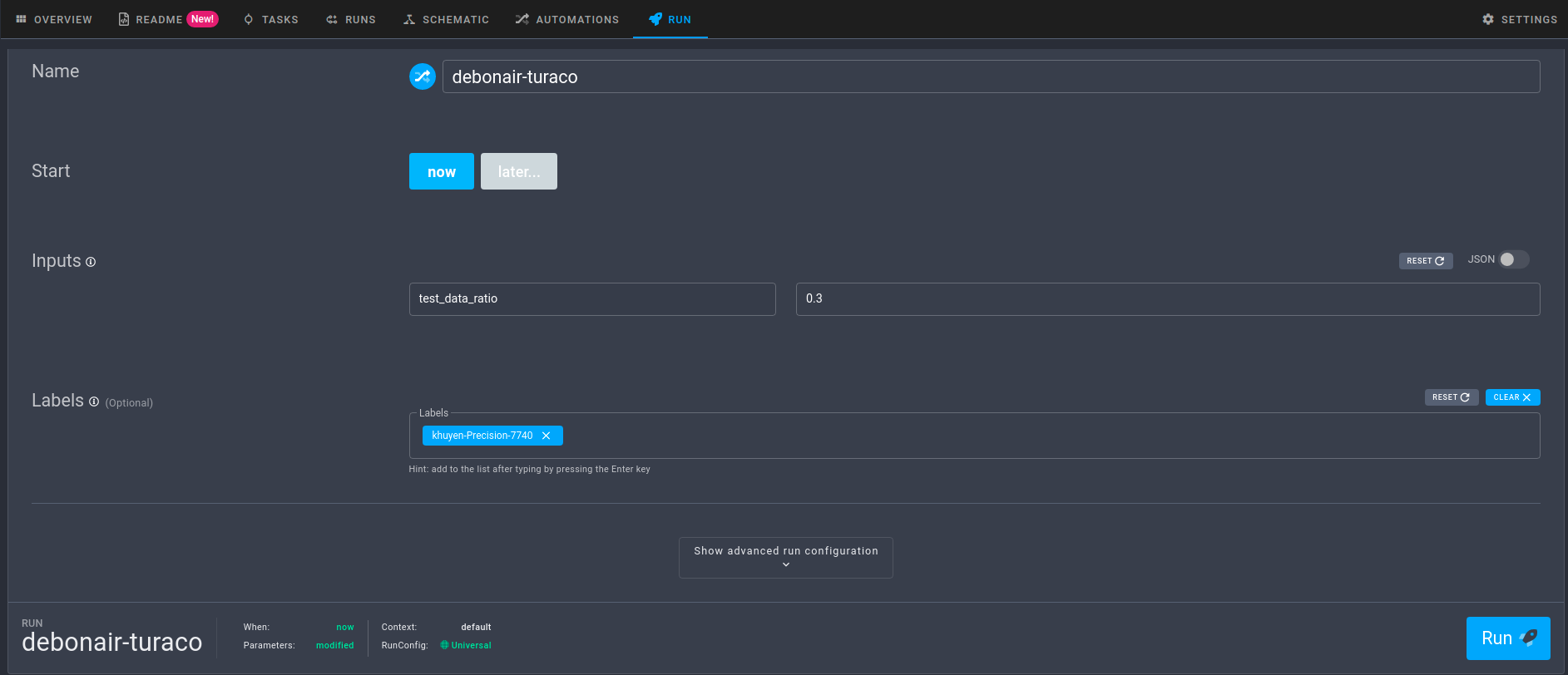
Quando estiver satisfeito com os parâmetros, basta clicar no botão Run para iniciar a execução.
5.1.3.4. Visualize o gráfico do fluxo de trabalho#
Clicar em Schematic fornecerá o gráfico de todo o fluxo de trabalho:
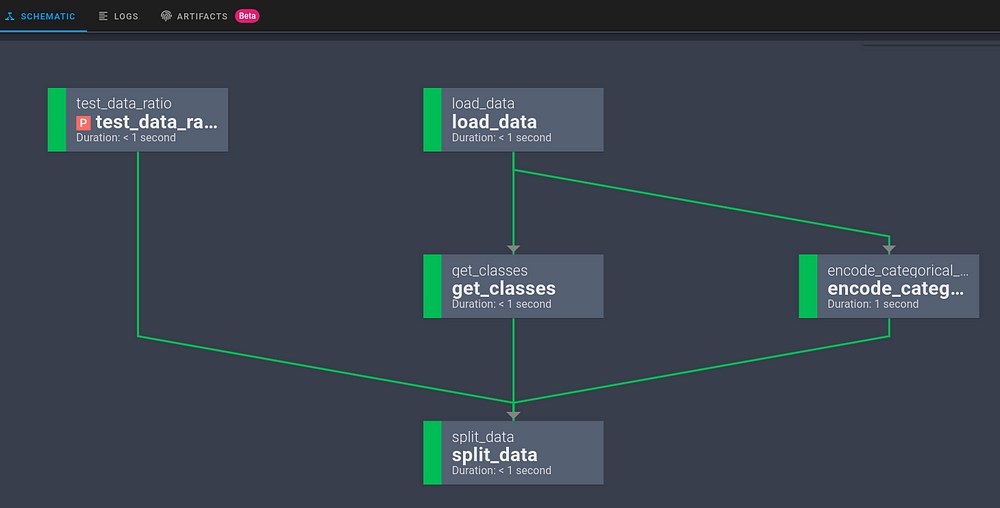
5.1.4. Outras características#
Além de alguns recursos básicos mencionados acima, o Prefect também fornece outros recursos interessantes que aumentarão significativamente a eficiência do seu fluxo de trabalho.
5.1.4.1. Cache de entrada#
Lembra do problema que mencionamos no início da seção? Normalmente, se a função get_classes falhar, os dados criados pela função encode_categorical_columns serão descartados e todo o fluxo de trabalho precisa ser iniciado desde o início.
No entanto, com o Prefect, a saída de encode_categorical_columns é armazenada. Na próxima vez que o fluxo de trabalho for executado novamente, a saída de encode_categorical_columns será usada pela próxima tarefa sem executar novamente a tarefa encode_categorical_columns:
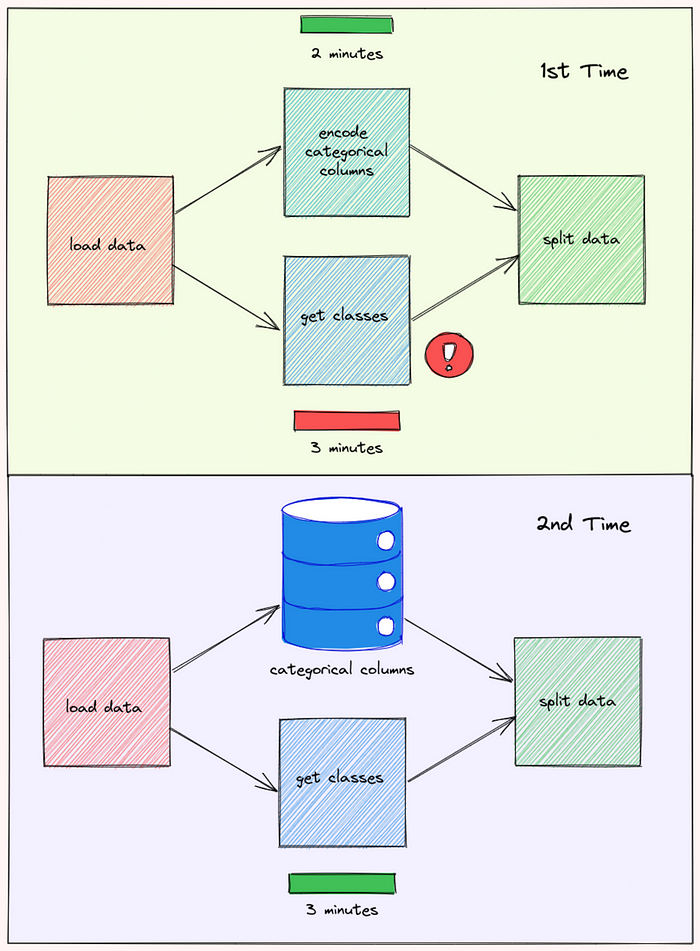
Isso pode resultar em uma grande redução no tempo necessário para executar o fluxo de trabalho.
5.1.4.2. Saída persistente#
Às vezes, você pode querer exportar os dados da sua tarefa para um local externo. Isso pode ser feito inserindo na função de tarefa o código para salvar os dados.
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
X_train, X_test, y_train, y_test = ...
import pickle
pickle.save(...)
No entanto, fazer isso dificultará o teste da função.
O Prefect facilita salvar a saída de uma tarefa para cada execução:
definindo o checkpoint para
True
$ export PREFECT__FLOWS__CHECKPOINTING=true
e adicionando
result = LocalResult(dir=...))para o decorator@task.
from prefect.engine.results import LocalResult
@task(result = LocalResult(dir='data/processed'))
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
"""Função para dividir o conjunto de dados Iris em conjuntos de treino e teste."""
X_train, X_test, y_train, y_test = ...
return dict(
train_x=X_train,
train_y=y_train,
test_x=X_test,
test_y=y_test,
Agora a saída da tarefa split_data será salva no diretório data/processed ! O nome será algo semelhante a isto:
prefect-result-2021-11-06t15-37-29-605869-00-00
Se você quiser personalizar o nome do seu arquivo, você pode adicionar o argumento target a @task :
from prefect.engine.results import LocalResult
@task(target="{date:%a_%b_%d_%Y_%H:%M:%S}/{task_name}_output",
result = LocalResult(dir='data/processed'))
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
"""Função para dividir o conjunto de dados Iris em conjuntos de treino e teste."""
...
O Prefect também fornece outras classes Result como GCSResult e S3Result. Você pode conferir a documentação da API sobre resultados aqui.
5.1.4.3. Use a saída de outro fluxo para o fluxo atual#
Se você estiver trabalhando com vários fluxos, por exemplo, fluxo data-engineer e fluxo data-science, convém usar a saída do fluxo data-engineer para o fluxo data-science.
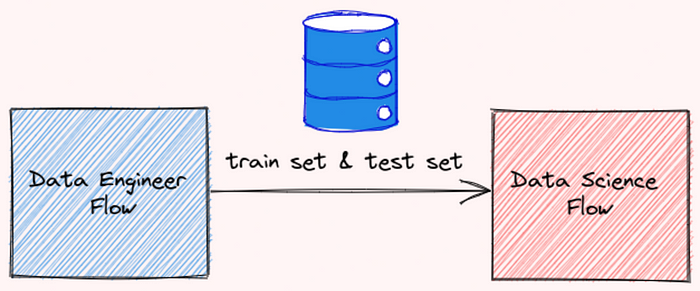
Após salvar a saída do seu fluxo data-engineer como um arquivo, você pode ler esse arquivo usando o método read:
from prefect.engine.results import LocalResult
train_test_dict = LocalResult(dir=...).read(location=...).value
5.1.4.4. Conectar fluxos dependentes#
Imagine este cenário: você criou dois fluxos que dependem um do outro. O fluxo data-engineer precisa ser executado antes do fluxo data-science
Alguém que olhou para o seu fluxo de trabalho não entendeu a relação entre esses dois fluxos. Como resultado, eles executaram o fluxo data-science e o fluxo data-engineer ao mesmo tempo, e encontraram um erro!
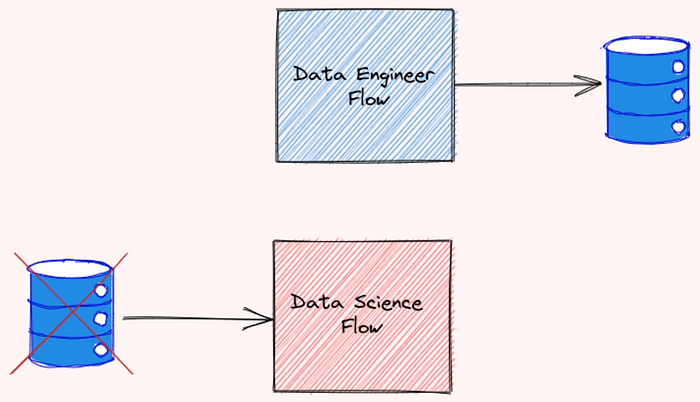
Para evitar que isso aconteça, devemos especificar a relação entre os fluxos. Felizmente, O Prefect facilita para fazermos isso.
Comece pegando dois fluxos diferentes usando StartFlowRun. Adicione wait=True ao argumento para que o fluxo seguinte seja executado somente depois que o fluxo anterior terminar de ser executado.
from prefect import Flow
from prefect.tasks.prefect import StartFlowRun
data_engineering_flow = StartFlowRun(flow_name="data-engineer",
project_name='Iris Project',
wait=True)
data_science_flow = StartFlowRun(flow_name="data-science",
project_name='Iris Project',
wait=True)
Em seguida, chamando data_science_flow no gerenciador de contexto with Flow(...). Use upstream_tasks para especificar as tarefas/fluxos que serão executados antes que o fluxo data-science seja executado.
with Flow("main-flow") as flow:
result = data_science_flow(upstream_tasks=[data_engineering_flow])
flow.run()
Agora os dois fluxos estão conectados como abaixo:

Muito legal!
5.1.4.5. Agende seu fluxo#
O Prefect também facilita a execução de um fluxo em um determinado momento ou em um determinado intervalo.
Por exemplo, para executar um fluxo a cada 1 minuto, você pode iniciar a classe IntervalSchedule e adicionar schedule ao gerenciador de contexto with Flow(...):
from prefect.schedules import IntervalSchedule
schedule = IntervalSchedule(
start_date=datetime.utcnow() + timedelta(seconds=1),
interval=timedelta(minutes=1),
)
data_engineering_flow = ...
data_science_flow = ...
with Flow("main-flow", schedule=schedule) as flow:
data_science = data_science_flow(upstream_tasks=[data_engineering_flow])
Agora seu fluxo será executado novamente a cada 1 minuto!
Saiba mais sobre as diferentes maneiras de programar seu fluxo aqui.
5.1.4.6. Logging#
Você pode registrar as declarações do print dentro de uma tarefa simplesmente adicionando log_stdout=True a @task:
@task(log_stdout=True)
def report_accuracy(predictions: np.ndarray, test_y: pd.DataFrame) -> None:
target = ...
accuracy = ...
print(f"Model accuracy on test set: {round(accuracy * 100, 2)}")
E você deve ver uma saída como abaixo ao executar a tarefa:
[2021-11-06 11:41:16-0500] INFO - prefect.TaskRunner | Model accuracy on test set: 93.33